College of Engineering Unit:
The Security and Exchanges Commission (SEC) has public documents of corporate filings with the SEC. Valuable trading information is available in these documents, but the documents are long and unstructured. Using Machine Learning and Natural Language Processing, our project can detect if a company is under investigation by the SEC at a faster and more accurate rate than the current procedure used by our project partner.
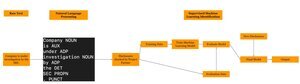
The documents contain relevant phrases for determining if a company is under investigation. Our project partner provided us with relevant phrases used for past identification. With these, we created a Natural Language Processing pipeline to tag and match patterns within the text documents
With several matched patterns, we created models of the documents using machine learning to classify new documents presented to the model. We used supervised machine learning comparing documents that our project partner had classified.
Our error rate on these documents is currently around 15%.
Expanding on this concept, our team decided to explore other methods of data gathering to get a more complete picture (and real time updates) of relevant information. As social media is playing an increasingly important role in our society, we decided that integrating Twitter monitoring would allow us to get up to date information and rumors on the happenings of the stock market. Another method that was explored in an attempt to collect more data was automated web scraping on various news sites. As many announcements in this day and age are seen on the news well before official disclosures and releases, our team believes that this feature will allow us to stay ahead of the game. Lastly, our team explored and implemented automated file monitoring. When a file is added to a specified folder, that added file will be automatically processed by our machine learning algorithm.