College of Engineering Unit:
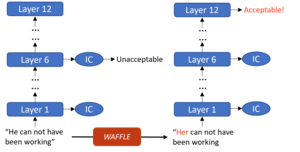
In this research, we evaluate the robustness of multi-exit language models against adversarial slowdown. To do so, we design a slowdown attack that generates adversarial text bypassing early-exit points. We use the resulting attack as a vehicle to conduct an evaluation of three multi-exit mechanisms with the GLUE benchmark. We show that our attack significantly reduces the computational savings provided by the three methods in both white-box and black-box settings. The more complex a mechanism is, the more vulnerable it is to adversarial slowdown. We also perform a linguistic analysis of the perturbed text inputs, identifying common perturbation patterns that our attack generates. Moreover, we show that adversarial training is ineffective in defeating our slowdown attack, but input sanitization with a conversational model, e.g., ChatGPT, can remove perturbations effectively. This result suggests that future work is needed for developing efficient yet robust multi-exit models.