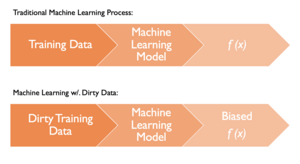
Problem Description
The overarching goal of my work is to remove the data cleaning process from the machine learning process. Data cleaning is one of the largest obstacles in the machine learning (ML) process. It has been estimated that nearly 60 percent of a data scientist's time is spent manually cleaning data. While it is widely known that extremely valuable insight can be gained from data, many users fail to harness this due to the high overhead cost of having to prepare and clean the data. The data cleaning step is unfortunately mandatory in the ML process. Training an ML model over dirty data would result in biased or inaccurate models. A biased or inaccurate model could have broad sweeping consequences due to the widespread adoption of ML. For example, law enforcement uses machine learning in image recognition. A biased or inaccurate model could end up with the wrong person charged with a crime.
With all of that being said: I aim to do exactly that without affecting the accuracy of the model with respect to its ground truth (model if trained over the data's clean counterpart).
Castor System
As a member of the IDEA Lab under Dr. Termehchy, I have worked on the Castor project which is a relational learning system that has proven effective at generating accurate models over heterogeneous data. Heterogenous data is data from separate sources that may not model the same information in the same format. This problem typically causes models to not learn novel information from disparate data sets. Castor uses similarity properties and generalization to understand relationships of the clean attributes without propagating the unclean aspects. After successfully producing Castor, I, along with my research team, have shifted our focus to expanding the generalization process used in Castor to build other machine learning systems with tolerance to dirty data.
Expanding to Decision Trees
Currently, we are building a modified decision tree system with tolerance to null values found in flat file data. Our solution generates candidate sets, versions of a certain data point that are automatically cleaned, to generalize common (clean) information about the data point. The system, which is under development, has already shown promise both in terms of effectiveness and efficiency. By increasing the time complexity of the decision tree algorithm slightly, we believe we can make the entire model tolerant to null values.
Impact
This line of inquiry and research is very important for machine learning to move forward. By reducing the time it takes to train effective and accurate machine learning models, we may begin to see ML adopted in far more places than it currently is. We have already seen impressive feats due to machine learning (think self driving cars, spam filtering, fraud detection, etc.), but just imagine how much more can be done if its more accessible everyone.

