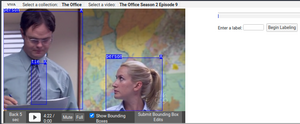
Our project makes it easier for people to label things in videos by teaching the computer how to recognize people and objects in videos.
As more and more people use applications like Netflix, Hulu, and Youtube to watch TV shows, the need for a way to better engage with the content grows. Recent developments in artificial intelligence (AI) have provided many new techniques for analyzing large amounts of video content, but utilizing them requires having datasets of annotated videos that aren’t readily available. Our capstone project aims to address the challenge of designing a new interactive user interface that effectively visualizes video data so that people can easily make sense of information in videos and accomplish search, annotation, and retrieval tasks.
Over the course of this past year, our team assisted Dr. Minsuk Kahng’s research group in developing a novel visual, interactive interface for searching, browsing, and annotating videos using interactive machine learning workflows. The application uses machine learning to recognize objects and characters for a set of TV shows and YouTube videos.
Our tool is a web-based system that combines various artificial intelligence techniques and human-centered interactive approaches and is usable on any web browser. The interface utilizes multiple machine learning, data mining, and deep learning techniques in order to bring novel features to the general public. For example, we built and trained image classification and object detection models, either from scratch with custom datasets or from a pre-trained model provided to us. Training these models means we’re teaching the computer to recognize what we would like it to see. For example, if we tell the computer a character appears in 100 different spots within an episode, it will eventually be able to recognize what the character looks like and automatically find them later. Since the model isn’t perfect, it won’t always be correct. But with our interface, people are able to continually train the model by removing or editing false appearances of some character or object.
In addition, our interface provides two interactive machine learning workflows to allow people to more easily and quickly annotate videos using either bounding boxes or video frames. The interface displays a timeline of character/object detection results obtained from the underlying models using modern information visualization techniques. People can then correct the model’s labeling suggestions so that the model becomes smarter and will help speed up the video annotation process.
We hope that this tool will help lower the entry barrier for up and coming dataset creators so they can quickly and easily integrate artificial intelligence models into their own applications. We also hope to bridge the gap between human workflows and AI workflows. In an ideal world, AI will help inform human decision making. As such, our application is meant to be as intuitive and transparent as possible, allowing people to interact with the various artificial intelligence tools at their own pace as their understanding of the systems grows.
In the future, Dr. Kahng’s research group plans to further improve this tool, open source the project, and publish results in research papers. Though we deviated from our initial design, which allowed avid TV watchers to interact with their favorite shows in new ways, we managed to keep most of the AI powered features that would allow this project to branch back into that territory in the future should the research group or a future capstone project wish to create a more consumer-focused application based on our work.

